ELF文件分析(七) 动态链接之PLT/GOT
0x01 PLT/GOT
在上节ELF文件分析(六) 动态链接之基础设计中,我们知道为了解决位置无关代码(PIC)访问外部符号的问题,需要使用PLT(过程链接表)和GOT(全局编译表)来动态解析共享的变量和函数。那么这两个表到底在哪里呢?
我们可以通过readelf输出段节信息然后grep来找找
1 | readelf -WSl ELF-file | grep -E ".got|.plt" |
下面是实例的情况
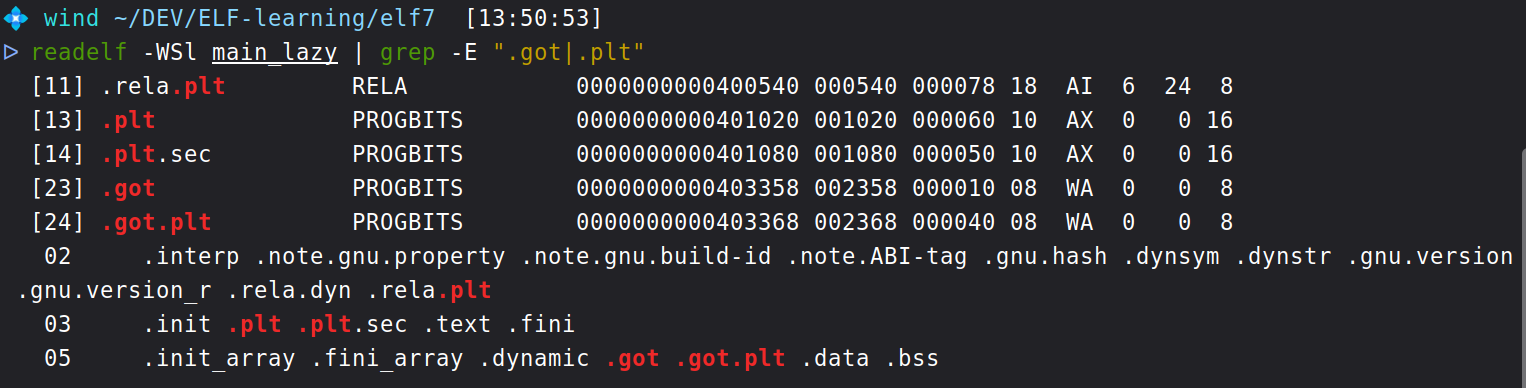
显然其中03是代码段,有.plt和.plt.sec个关于PLT表的节;05是数据段,有.got和.got.plt两个关于GOT表的节。对于这几个节,其作用不尽相同。下面罗列了我们可能见到的PLT/GOT的节及其属性。
| 节名 | 所属段属性 | 作用 |
|---|---|---|
| .plt | 可读可执行 | 过程链接表。这是动态链接函数的入口点。当程序第一次调用一个外部函数时,实际上是跳转到该函数在
.plt
中对应的条目。这个条目中的代码负责解析函数的真实地址(通过
.got.plt 和动态链接器),然后跳转过去。 |
| .plt.sec | 可读可执行 | PLT 的安全增强部分。这是 .plt
的一个子集,用于实现一些安全特性,比如 Intel 的间接分支跟踪(Indirect
Branch Tracking, IBT),作为控制流完整性(Control-Flow Integrity,
CFI)的一部分,以防止某些类型的代码重用攻击。 |
| .plt.got | 可读可执行 | (待补充) |
| .got | 可读可写->只读 | 全局偏移表。主要用于存放在程序中引用的全局变量的地址。这些变量的地址在链接时是未知的,需要在程序启动时由动态链接器填充。 |
| .got.plt | 可读可写->只读 | 用于 PLT
的全局偏移表。这个表专门存放外部函数的地址。它的条目初始时指向
.plt
中的下一条指令(即地址解析代码),在函数第一次被调用并解析成功后,动态链接器会将该条目更新为函数的真实内存地址。 |
note
.got一般是用来保存全局变量的,但是在严格绑定的情况下可能没有.got.plt节,而是由.got来保存全局变量和外部函数。
0x02 IDA
接下来的内容需要调试,通过设置断点来搞清楚整个延迟绑定的过程。
我们需要一款叫做IDA的工具,网上有非常多关于它的泄漏版本。IDA PRO相较于IDA FREE而言会多一些架构的支持以及Hexrays的反编译功能。不过这里我们只使用其来看x64的反汇编代码和进行调试,因此IDA的版本不是问题。Free版本可以在这里找到https://hex-rays.com/ida-free。
IDA在提供静态分析外还提供了本地和远程的调试器组件,相较于gdb而言上手更快,学习成本更低。
0x03 延迟绑定
1. 源码简要浏览
源码依然可以在我的仓库找到,下面是延迟绑定构建的源码部分:
1 | # Makefile |
1 | // main.c |
1 | // libtest.c |
1 | // libtest.h |
2. 延迟绑定下第一次触发
整个程序的延迟绑定发生在外部函数调用的过程中。外部函数第一次的调用时,GOT表中还没有对应的地址,因此会先到PLT表中进行解析,然后填入字段。在上面的主函数代码中func_a被先后调用了两次,func_b被调用一次,而func_c没有被调用。我们主要分析func_a的两次调用过程。
首先将程序用ida打开,然后在主函数中在两个call func_a处设置断点,断点保证了代码在执行这条指令前会进行中断处理。
设置好断点后,选择上方绿色三角箭头右侧复选框的调试器为local Linux debugger,点击绿三角运行。
程序会自动在断点处停止,这时候我们可以通过F7单步运行,看看到底发生了什么。
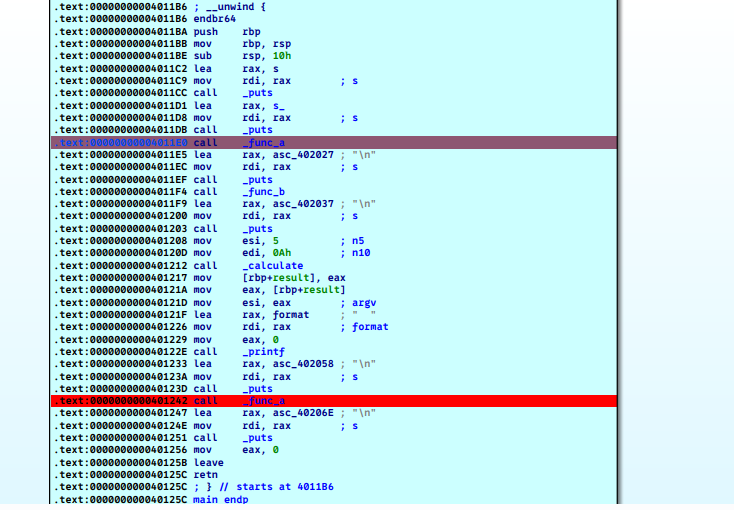
程序call指令执行后的第一跳到了.plt.sec节,如下图所示:
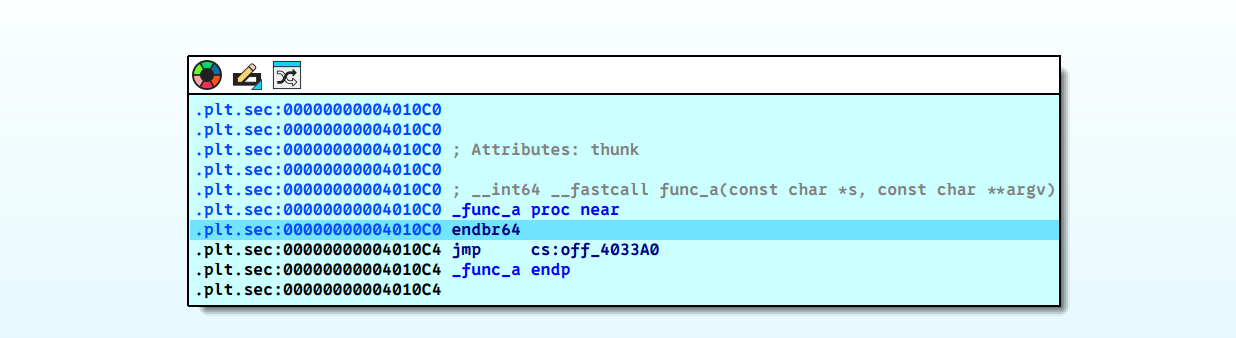
info
endbr64属于英特尔控制流强制技术(CET)的一部分,CET 技术主要由影子堆栈 (Shadow Stack, SS) 和间接分支跟踪 (Indirect Branch Tracking, IBT) 组成。后者保证了跳转的地址必须要有endbr指令否则就会产生异常。这样能有效避免攻击者复用函数内部代码的部分进行攻击。
然后接着是一次jmp,这时候终于到了plt表中的一个神秘函数sub_401070
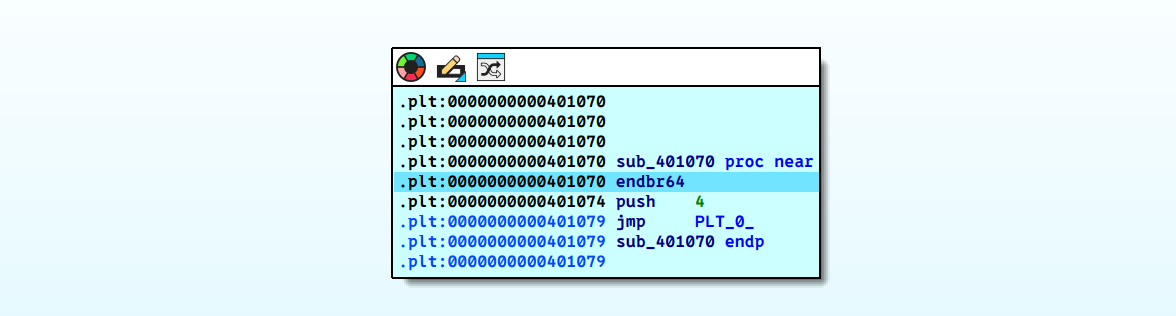
注意,这个函数中的跳转到的位置我进行了重命名,正常情况下你那边应该是JUMPOUT_w,实际上它也是plt表的第一个字段,所以叫做PLT[0]是没有任何问题的。对于push 4中的4是一个非常关键的数字,它指示了func_a在重定位表中的具体情况。
接着跟进,我们跳到了PLT[0]中,然后其中的代码是一次push和一次jmp,然后这两个地址相差正好一个字(64位下的8字节)。实际上这两个地址如果你点击进入可以看到GOT表中的第二和第三项。继续F7单步执行,这次我们到了非常重要的一个函数_dl_runtime_resolve (_dl_runtime_resolve_xsavec),这个函数会保存当前的所有寄存器到栈保存上,然后调用_dl_fixup这个关键函数完成重定位的操作
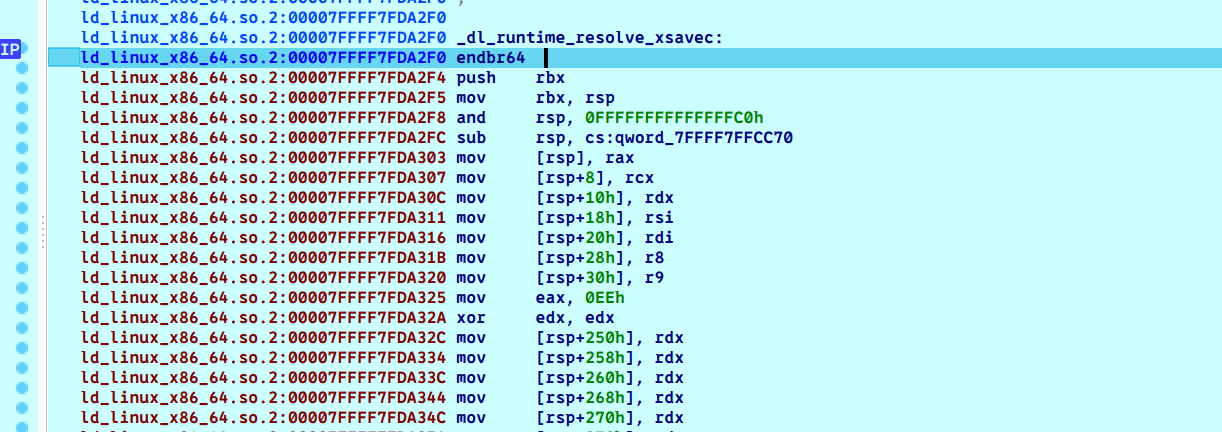
接着我们按F8离开然后一步步离开ld_linux_x86_64.so.2这个动态链接库,最后一个jmp r11指令完美的把我们送到了func_a的位置
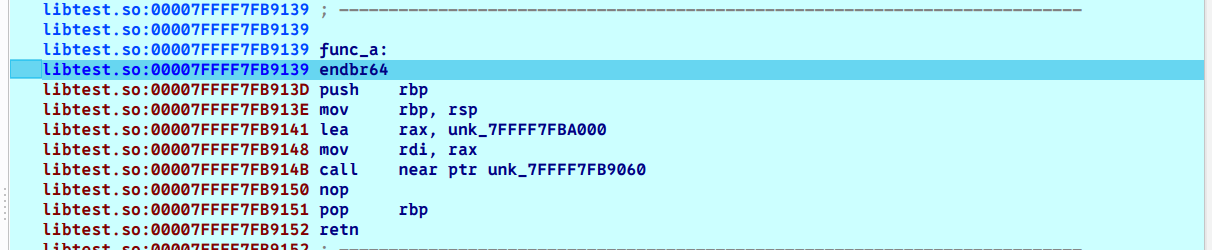
我们继续F8步过回到主程序,至此,第一次触发正式结束。
3. 延迟绑定下第二次触发
我们直接按F9到第二处的断点,然后按照上面的流程继续进行,然后你会在.plt.sec节跳转前发现不一样的东西。将鼠标指针轻轻放在off_4033A0的地方,看对应的位置对应的值是多少。
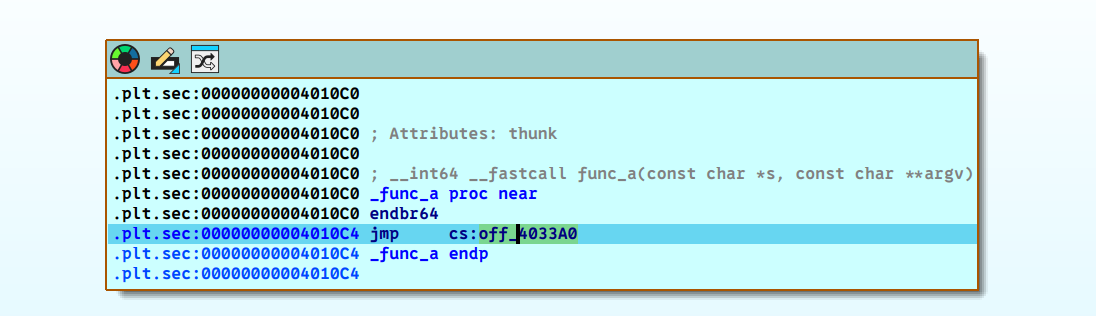
芜湖!同样是jmp cs:off_4033A0,这一次跳转到的位置不再是当时那个带有push 4的神秘函数sub_401070了,而是变成了func_a的值。由于是动态加载的,这个值运行时不能完全确定,但是无论怎样,都是我们刚才执行过的那个函数。
4. 延迟绑定总结
第一次触发的路径
1 | call func_a@plt # func_a@plt位于.plt.sec |
第二次触发的路径
1 | call func_a@plt # 位于.plt.sec |
这说明一开始的时候,got表(.got.plt节)还没有func_a的地址,所以需要调用_dl_runtime_resolve进行解析,然后进行修改。
这样做的好处是不需要获取所有函数的地址进行绑定,一定程度上减少了启动的时间开销,而是在函数实际被调用的第一次进行绑定,后续无需绑定。这在动态库函数和变量非常多,但是实际上使用的数量少的时候是非常有效的一个优化。
note
这里没有详细解析为什么是push 4,有兴趣的读者可以自行研究_dl_runtime_resolve的代码,搞清楚链接器是如何通过这个4来找到对应的函数的。同时有个比较有意思的问题,如果这个数字不是4而是被换成了如func_b所对应的2,那么下一次func_a的过程中会使用的函数是哪一个。
0x04 立即绑定
不同与延迟绑定,立即绑定在动态链接器进行处理的过程中会一次性处理所有got表的地址。
有人可能会问,现在既然有效率更高的延迟绑定,为什么还要再讲立即绑定呢?事实上这与安全机制有关系,如果got表的权限为只读,那么在动态链接器绑定的阶段就会出现问题。那好,我们只能先设置为可读可写。但是,当用户的程序被恶意代码利用的时候,很可能就会修改got表来实现函数的劫持,因为我们当时是直接jmp到got表中的一个地址了。
现代的解决方式是先作为可读可写装载,然后动态链接器解析完成后重新设置为只读,这样就保护了got表。具体而言,这个机制叫做RELRO。我们后续会有一个专题来谈谈ELF上的安全机制。
0x05 小问题
关于PLT/GOT机制
- 尝试在延迟绑定的程序中对func_b进行研究,并回答对func_a的绑定会造成影响吗?
- 尝试通过修改延迟绑定中got表中的字段实现控制流劫持。
- 分析
push 4中4所代表的具体含义。 - 思考一下,有没有比RELRO更好的、能解决got表劫持问题的安全机制?