ELF文件分析(四) 重定位
0x01 重定位简介
1. 什么是重定位
参考ELF(5)手册
重定位(Relocation)是将符号定义和符号引用进行连接的过程。可重定位文件需要包含描述如何修改节内容的相关信息,从而使得可执行文件和共享目标文件能够保存进程的程序镜像所需的正确信息。重定位条目就是上述的相关信息。
Relocation is the process of connecting symbolic references with symbolic definitions. Relocatable files must have information that describes how to modify their section contents, thus allowing executable and shared object files to hold the right information for a process’s program image. Relocation entries are these data.
上面的描述有点晦涩,本质就是让程序中引用的符号能找到定义的位置。
2. 为什么要有重定位
如果代码文件A需要用到代码文件B的函数,在C语言中,我们会通过#include宏来进行头文件包含,从而引用其中的全局变量或者是函数。但在实际编译的过程中,代码A和代码B编译成目标文件的过程是独立进行的,每个都会先独立编译成目标文件,最后再链接成可执行文件。那么在原先的代码文件A生成的目标文件中,又如何才能保留使用代码文件B中函数的信息给链接器进行下一步处理呢?
这就是我们本次的话题——重定位所解决的问题。
3. 两种链接方式
下面聊两种不同的链接方式,它们都使用了重定位技术来确保程序正常运行。
静态链接(Static Linking)
最直接的链接方式。链接器对需要链接的目标文件和静态库进行扫描、符号解析、将节进行合并(如.text节和.text节合并)、重定位计算每个函数运行时的虚拟地址、修改每个外部函数或变量的引用,使其指向正确的地址、生成可执行文件。
动态链接(Dynamic Linking)
更灵活的链接方式。链接器这次不会直接去复制函数引用的代码了,而是创建一个存根(Stub)作为占位符,而这个存根中记录函数及其库名用于调用。
运行时由于动态链接方式的特殊性,加载器启动程序后会运行动态链接器(一般是ld.so)来执行重定位功能,这部分还涉及到plt和got的内容,后续会一一进行仔细地说明。
0x02 重定位表
1 | # readelf解析 -r 重定位条目 |
还记得我们之前在段节比较和节头表中呈现的那个大表格吗?其中有一个特别的节(.rel.*),这就是我们重定位表的位置。
在看下面结构体之前,我们可以先思考一下,假设你现在有两个目标文件a.o和b.o,现在你需要保证a.o中所有调用b.o中代码的地方能找到对应的地址,你会需要哪些信息。
显然你至少要有这些:
- 引用的位置(哪里用了b的东西)
- 引用的东西的信息 (b的什么东西)
现在我们来看看重定位表项的结构,由于有的部分需要添加addend字段来提供额外信息,因此有Rel和Rela两种。
1 | // Rel在32位中常见,没有r_addend而是通过隐式加数来完成 |
note
Rel和Rela的区别在于隐式加数,现在的64位程序多用Rela。隐式加数本质上是将r_addend写进了需要调整的代码之中。
实例
你可以在远程仓库中下载到这个例子。
1. 先看源码
1 | // a.c |
1 | // b.c |
1 | // b.h |
1 | # Makefile |
2. 目标文件分析
我们首先来分析a.o中符号表的位置
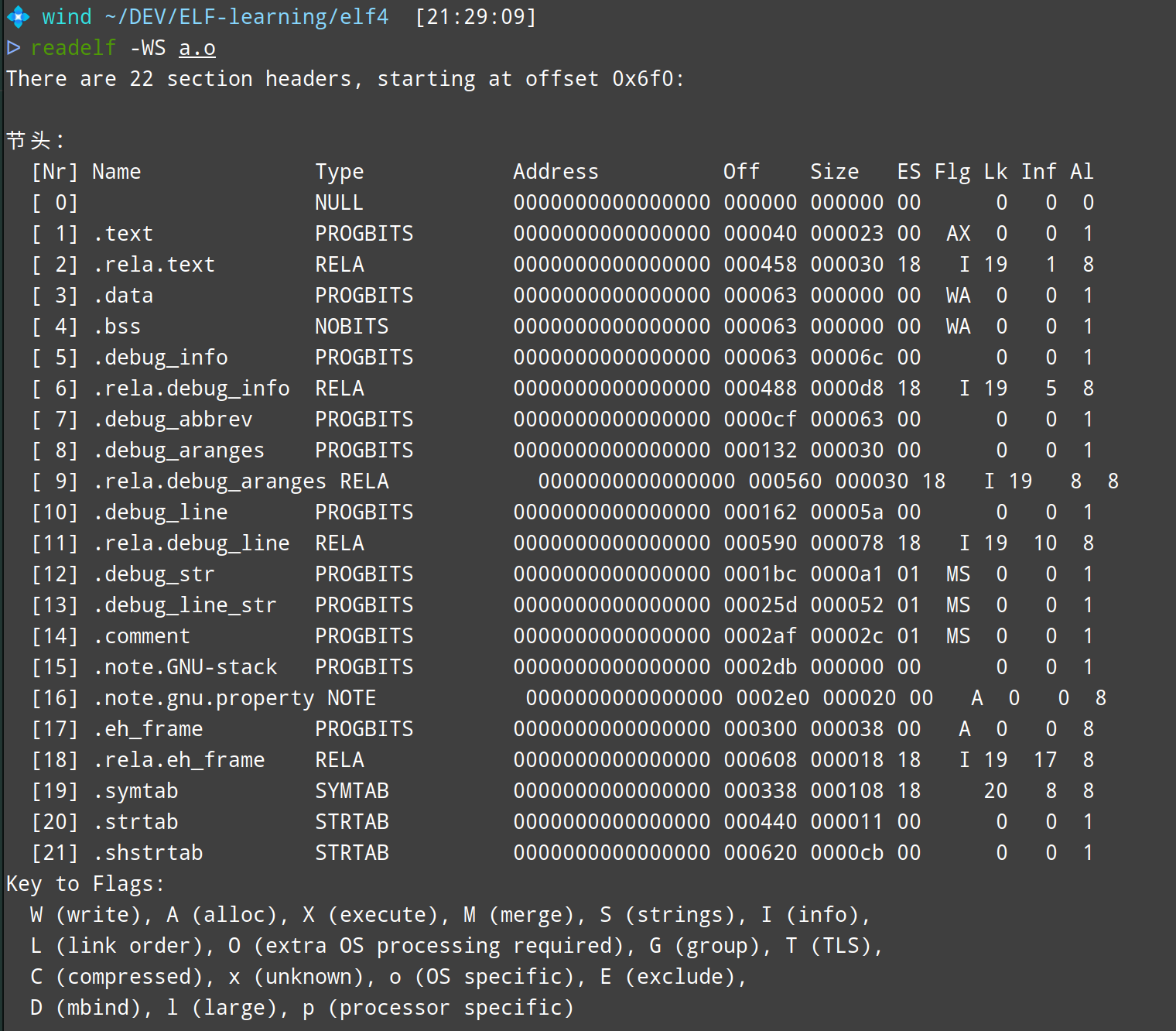
注意一下类型是RELA,这些就是重定位表的位置。
可以看到上面展示有五个重定位的节,我们只分析.rela.text
在imhex中找到文件偏移为0x458、大小为0x30部分如下
1 | Hex View 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F |
显然根据先前的Elf64_Rela来解析表项
1 | struct Elf64_Rela rel1 = { |
note
注意类型,r_addend是int_64有符号,所以0xFFFFFFFFFFFFFFF8得按补码解析成-0x8。(你可以通过0xFFFFFFFFFFFFFFF8 + 0x8 = 0x10000000000000000显然的看出负数的数值)
3. 在.text节中找到修补的这部分
我们先来看第一个部分,位置是.text节的第0x0A(10)个字节,类型由r_info的低4字节可以看到是0x2,由于我们的机器是AMD64位的,因此我们要查询R_X86_64然后找到宏值为2的。事实上是下面这个
1 |
所以说这是32位有符号的整数的重定位信息,现在我们来看看在.text节中的情况。你可以回看上面readelf -WS的结果来确定其位置,是文件偏移0x40处大小0x23的部分。显然这个节的内容我们无法理解,必须通过工具进行反汇编才能知道内容。
1 | Hex View 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F |
这时候就必须介绍一个非常有用的工具了,叫做objdump了,功能是进行反汇编。我们现在只需要知道其几个简单的选项即可,-f看文件头信息,-p看程序头信息,-h看节表头信息,-d进行反汇编,-r显示重定位表,而-M能指定汇编代码的风格(AT&T or Intel)
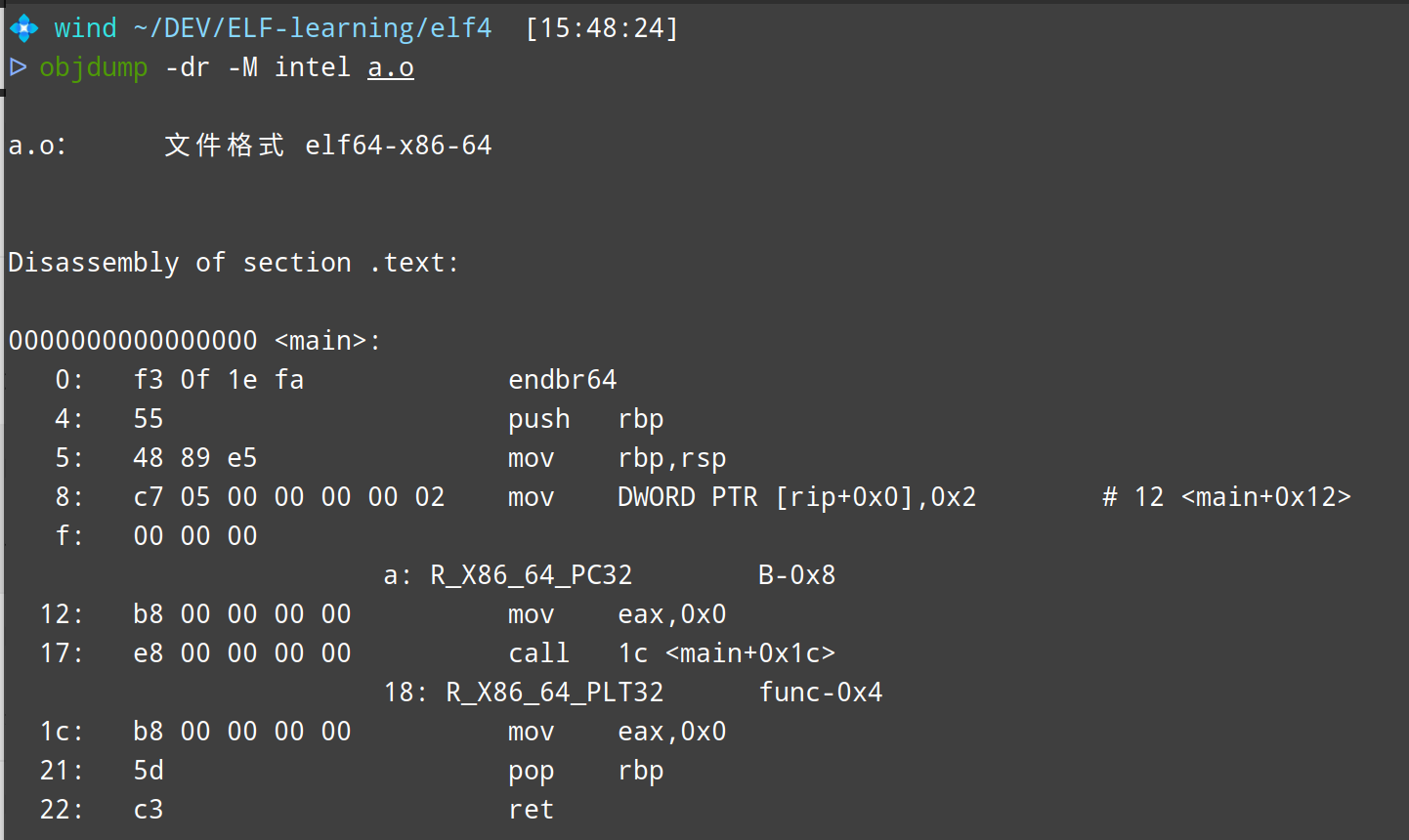
在上面的图片中我们可以看到main函数大小为0x23,其中重定位的两个部分需要我们尤其注意。注意看0x8处的这条指令,mov DWORD PTR [rip+0x0], 0x2,其机器码c7 05 00 00 00 00 02 00 00 00中从0xa开始有4个字节的00,这就是上面的[rip+0x0]的来源,由于重定位代码不知道这个变量的位置,所以只能用00来先占位。如果是Rel类型,这里可能不是00,需要存数据来保存隐式加数的信息。而后面进行函数的重定位也是一样的道理,只不过这次使用的是call指令而已。
4. 链接器如何确定要修改的值
在此之前,我们可以用odjdump看看链接后的文件的两个重定位部分的情况。
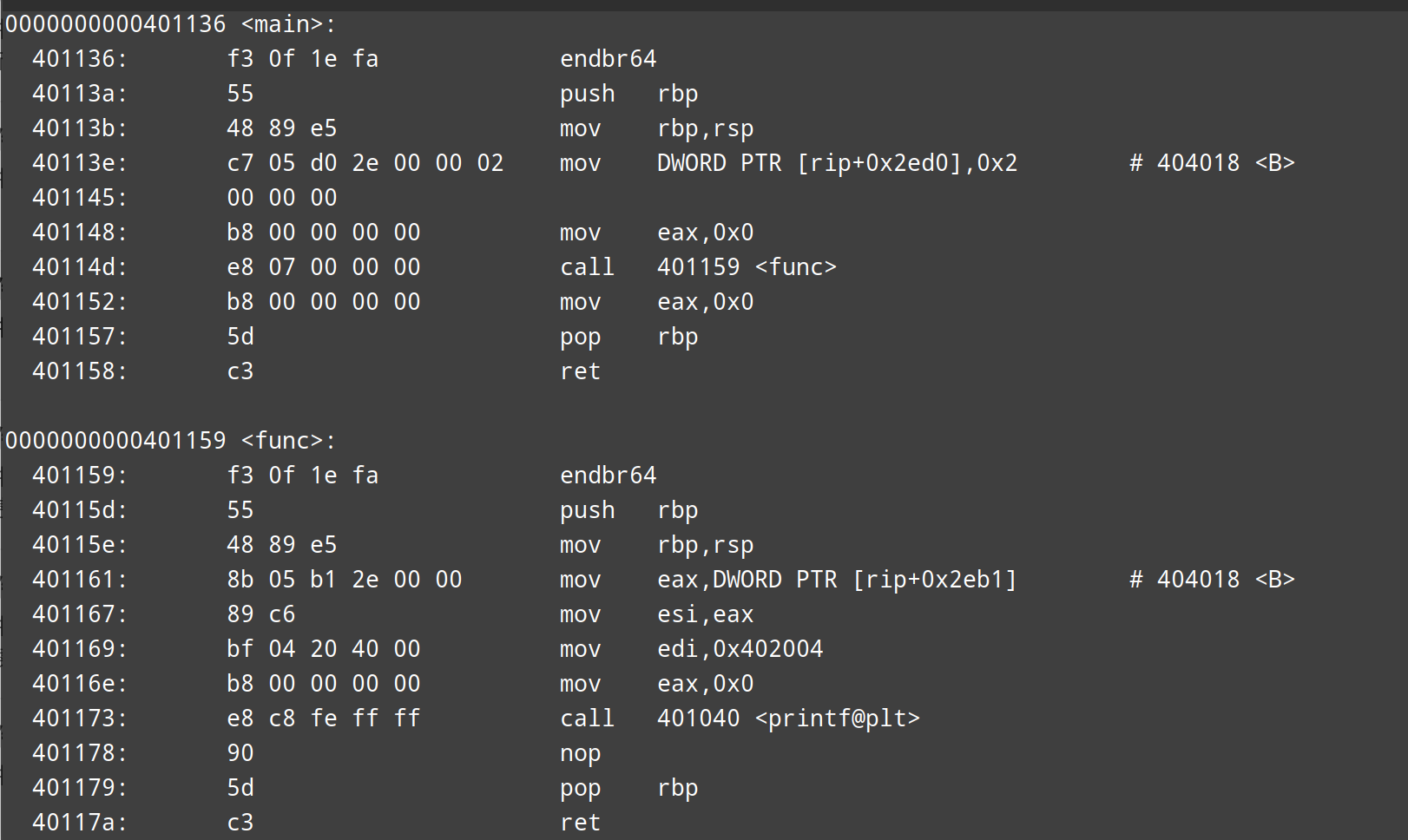
可以看到,链接后的程序完美的修补了这几个部分。现在问题来了,这几个值是怎么确定出来的,还有之前说的加数到底是什么?没事,我们这就来解释解释。
在此之前我们需要了解链接器的工作原理。链接时,链接器会执行下面这些操作:
- 收集所有输入文件
- 符号解析
- 节的合并与布局
- 重定位计算和修改
- 生成文件头、程序头和节表头
其中我们可以通过链接器脚本来控制输出文件的内存布局,从而纯手工地通过a.o和b.o计算出重定位的值。链接器脚本主要影响的是上面的第三步,但是它比较高级且不便于消化,我们后面有足够的知识来再来模拟一次完整的链接器流程。
话虽如此,S+A-P规则还是得仔细讲讲,这是重定位修改最核心的部分,能帮我们更好理解Rela的设计。
info
S+A-P 规则是计算重定位值的核心公式。它适用于大多数基于 PC 相对寻址的重定位类型(如 R_X86_64_PC32)。
- S: 符号(Symbol)的最终运行时地址。
- A: 加数(Addend),一个在重定位项中指定的常量值。它用于调整计算结果,例如修正指令长度带来的偏差。
- P: 修正位置(Place),即指令中需要被链接器填入计算结果的地址。
-
rip:
CPU在执行某条指令时rip寄存器的值是下一条指令的地址。
重定位的目标是计算出一个offset,使得 指令执行时rip + offset正好等于S。 即:S = rip + offset => offset = S - rip。 链接器在静态分析时无法知道rip的确切值,但它知道P的值,也知道rip和P之间的关系。对于大多数指令,rip的值等于P加上指令中偏移量字段的长度。链接器用P来近似rip,并通过A来补偿。
最终,链接器计算出S + A - P的值,并将这个结果写入到文件中的P地址处。
现在,你能理解为什么常量加数是-8了吗?对于特殊的mov指令而言,修正位置P位于代码段偏移0x0A的位置,而mov指令进行后的rip是0x12,两者之差即为加数A。事实上,编译器是知道加数A而不知道rip的,这里只是个简单的小推导。
5. 链接器怎么知道到哪里找
这个部分就涉及到上一节中我们的符号了。在链接器进行符号解析的过程中,链接器会扫描并处理所有输入文件的符号表并构建一个全局的符号表,在这个过程中:
- 它看到
a.o中有一个对符号 B 的引用 - 它看到
b.o中有一个对符号 B的定义 - 由于链接器中的工作区内只有这两个关于B的符号,因此不存在符号上的冲突
这样,它就能找到符号的来源了。下面是两者的符号表,注意观察B和Ndx的值。
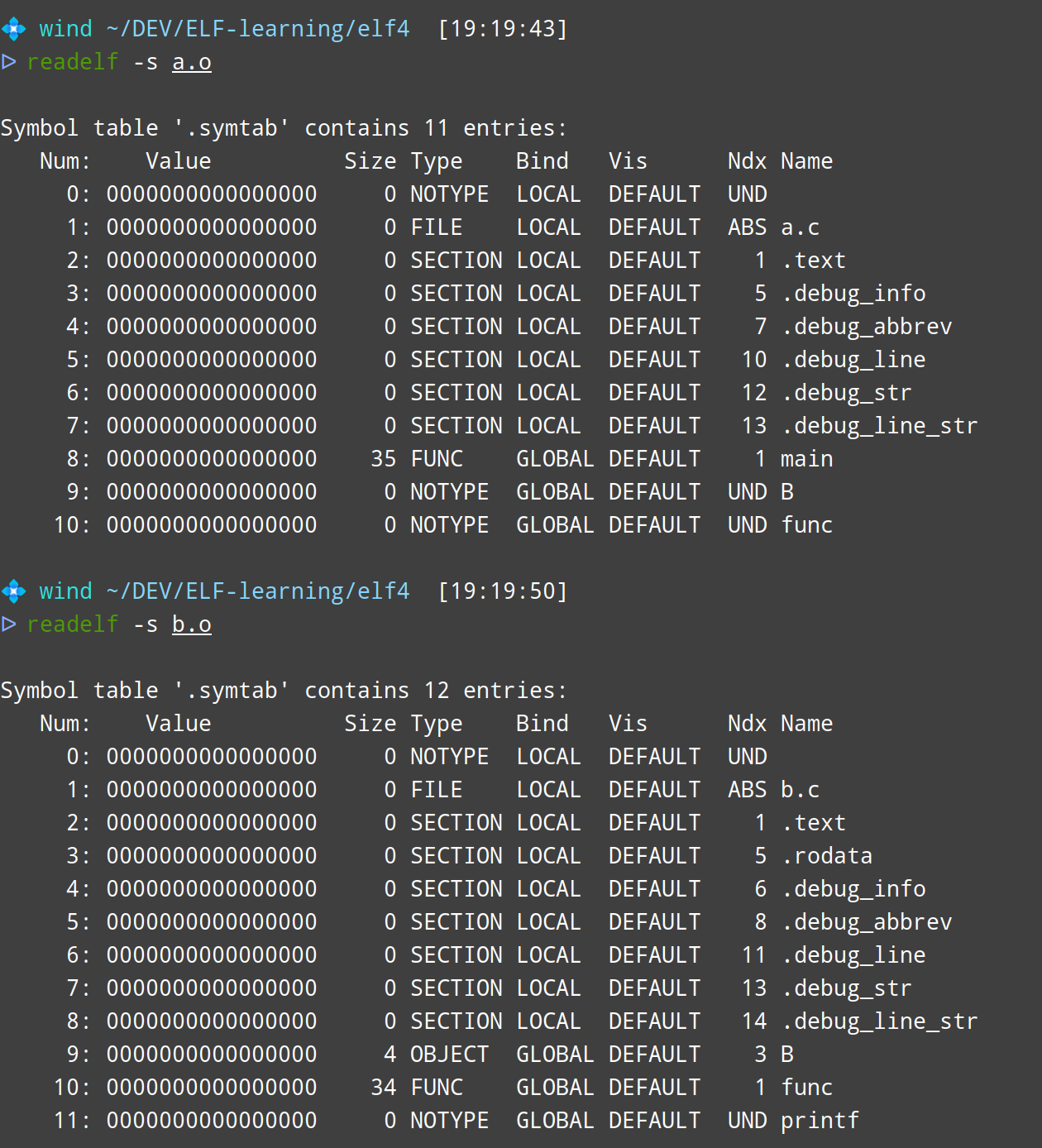
info
链接器符号解析情况
- 多强符号,直接报错
- 单强符号任意多弱符号,选择强符号
- 多弱符号,选择内存占有最大的一个
- 无符号,报错未定义
0x03 小问题
关于重定位表
- 根据上一节中关于符号表的知识,通过r_info的高位部分找到对应的符号
- 计算出上面的实例链接后
func的S、A、P的值 - 自主研究32位,分析Rel和Rela的区别,看看如何保存隐式加数的
- S+A-P规则适用于相对寻址修正,那绝对寻址修正呢?